Pakete

Um uns die Arbeit in R nicht schwerer als nötig zu machen, nutzen wir einige Pakete, die aufeinander abgestimmt sind und tolle Funktionen bieten. Alle R-Pakete sind frei verfügbar und können mit dem Befehl install.packages("<PACKAGE>") installiert werden. Um sie in einer R-Session zu nutzen, müssen sie mit dem Befehl library(<PACKAGE>) “angehängt” werden.
tidyverse
![]()
Das Tidyverse (Wickham et al., 2019) ist ein Verbund von Paketen, der das Arbeiten in R auf das angenehmste erleichtert. Diese sind aufeinander abgestimmt, benutzen einheitliche Syntaxen und beheben einige Marotten von base R.
Nach jeder frischen Installation von R sollte man somit diesen Befehl ausführen:
Das Tidyverse ist unter anderem um die Idee “sauberer” ( = tidy) Daten entstanden. Was genau tidy data ist, wird beim data wrangling deutlich. Nur so viel vorab: tidy data unterscheidet sich von der “herkömmlichen” Darstellung von Daten, wie etwa in SPSS.
Das Tidyverse bietet nun alle Instrumente, um alle Schritte dieses Workflows zu durchlaufen: 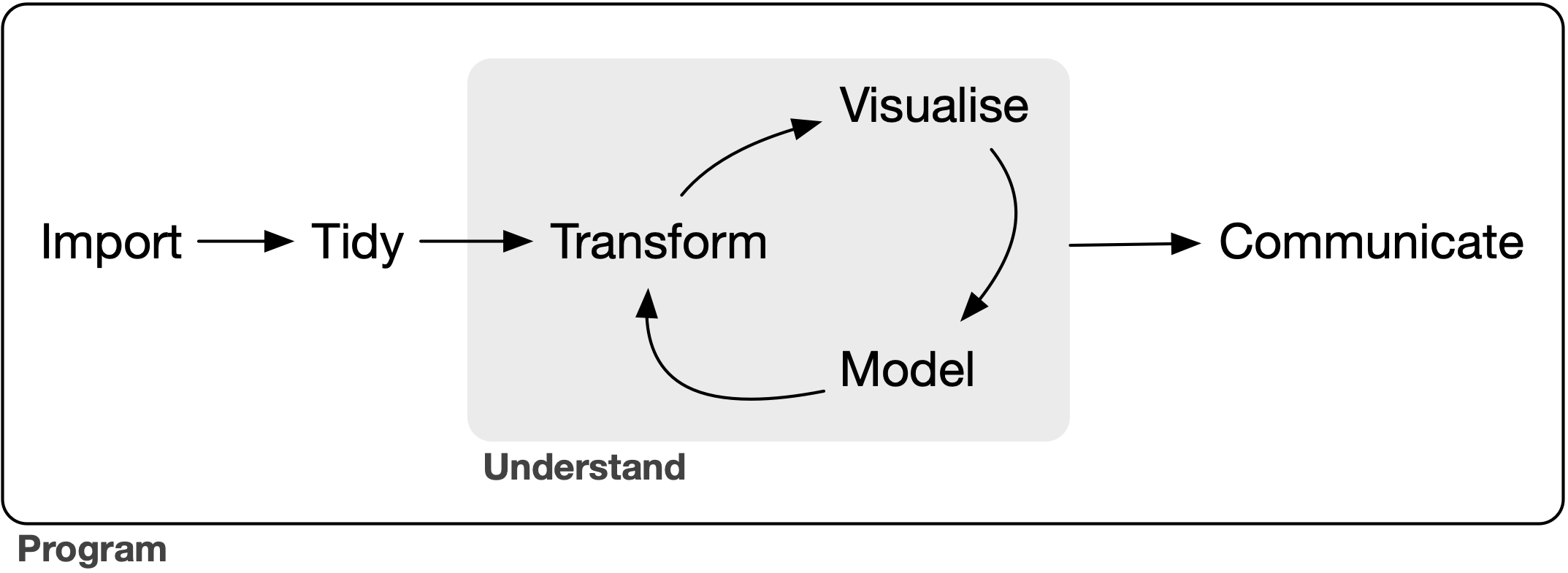
rstatix
Eine Ausnahme sind die Modelle, also unsere statistischen Tests. Für diese gibt es in R hunderte Pakete. In R gibt es viele Wege zum Ziel, jedoch einfachere und schwierigere. Einer der einfachsten Wege, um statistische Standard-Verfahren einzusetzen, und dann noch abgestimmt auf das Arbeiten im Tidyverse, ist das Paket rstatix (Kassambara, 2020). Installiert wird es, wie alle anderen Pakete mit:
janitor
Den Hausmeister, also das Paket janitor (Firke, 2020), wird hauptsächlich zur Bereinigung von Variablennamen genutzt und formatiert diese einheitlich im “snake case”-Format (siehe auch die Informationen zum Stil). Auch janitor ist im Tidyverse-Framework zuhause:
# Aus unsauberen Variablen-Namen...
unclean_names <- tibble(
"First name" = "x",
"LastName" = "y",
"DOB" = "z",
"BDI_1?" = 1,
"BDI_2" = 2,
"bdi_3" = 3
)
# ... werden saubere, einheitliche
clean_names(unclean_names)## # A tibble: 1 x 6
## first_name last_name dob bdi_1 bdi_2 bdi_3
## <chr> <chr> <chr> <dbl> <dbl> <dbl>
## 1 x y z 1 2 3costatcompanion
Auf das Arbeiten mit dieser Website abgestimmt ist das Paket costatcompanion – der perfekte Begleiter für die Kammer der Statistik. Das Paket enthält kleinere Hilfs-Funktionen und vor allem alle behandelten Datensätze. Es its nicht über CRAN verfügbar und muss von GitHub installiert werden. Eingebunden wird es über den normalen library() Befehl.
skimr
Mit skimr (Waring et al., 2020) können wir uns auf einfache Weise umfangreiche deskriptive Statistiken ausgeben lassen. Für den Datensatz mtcars sieht das beispielwesie so aus:
| Name | mtcars |
| Number of rows | 32 |
| Number of columns | 11 |
| _______________________ | |
| Column type frequency: | |
| numeric | 11 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| mpg | 0 | 1 | 20.09 | 6.03 | 10.40 | 15.43 | 19.20 | 22.80 | 33.90 | ▃▇▅▁▂ |
| cyl | 0 | 1 | 6.19 | 1.79 | 4.00 | 4.00 | 6.00 | 8.00 | 8.00 | ▆▁▃▁▇ |
| disp | 0 | 1 | 230.72 | 123.94 | 71.10 | 120.83 | 196.30 | 326.00 | 472.00 | ▇▃▃▃▂ |
| hp | 0 | 1 | 146.69 | 68.56 | 52.00 | 96.50 | 123.00 | 180.00 | 335.00 | ▇▇▆▃▁ |
| drat | 0 | 1 | 3.60 | 0.53 | 2.76 | 3.08 | 3.70 | 3.92 | 4.93 | ▇▃▇▅▁ |
| wt | 0 | 1 | 3.22 | 0.98 | 1.51 | 2.58 | 3.33 | 3.61 | 5.42 | ▃▃▇▁▂ |
| qsec | 0 | 1 | 17.85 | 1.79 | 14.50 | 16.89 | 17.71 | 18.90 | 22.90 | ▃▇▇▂▁ |
| vs | 0 | 1 | 0.44 | 0.50 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 | ▇▁▁▁▆ |
| am | 0 | 1 | 0.41 | 0.50 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 | ▇▁▁▁▆ |
| gear | 0 | 1 | 3.69 | 0.74 | 3.00 | 3.00 | 4.00 | 4.00 | 5.00 | ▇▁▆▁▂ |
| carb | 0 | 1 | 2.81 | 1.62 | 1.00 | 2.00 | 2.00 | 4.00 | 8.00 | ▇▂▅▁▁ |
Mit nur einem Befehl bekommen wir so eine klar strukturierte Übersicht über die Dimensionen des Datensatzes, sowie deskriptive Statistiken zu allen Variablen, getrennt nach Variablen-Typ. Im diesem Datensatz sind alle Variablen nummerisch (“numeric”) und so bekommen wir die Anzahl fehlender Werte, den Mittelwert, die Standardabweichung, die Range (p0 und p100 sind das 0%, bzw. das 100% Perzentil, also der niedrigste und der höchste Wert) und ein inline Histogramm, um die Verteilung grob abzuschätzen. Auch skimr ist im Tidyverse-Framework zuhause.
Literatur
Firke, S. (2020). janitor: Simple Tools for Examining and Cleaning Dirty Data. https://CRAN.R-project.org/package=janitor
Kassambara, A. (2020). rstatix: Pipe-Friendly Framework for Basic Statistical Tests. https://CRAN.R-project.org/package=rstatix
Waring, E., Quinn, M., McNamara, A., Arino de la Rubia, Eduardo, Zhu, H., & Ellis, S. (2020). skimr: Compact and Flexible Summaries of Data. https://CRAN.R-project.org/package=skimr
Wickham, H., Averick, M., Bryan, J., Chang, W., McGowan, L., François, R., Grolemund, G., Hayes, A., Henry, L., Hester, J., Kuhn, M., Pedersen, T., Miller, E., Bache, S., Müller, K., Ooms, J., Robinson, D., Seidel, D., Spinu, V., … Yutani, H. (2019). Welcome to the Tidyverse. Journal of Open Source Software, 4(43), 1686. https://doi.org/10.21105/joss.01686